Faculté Informatique & Communications
Cours de Programmation C++ -- J.-C. Chappelier
|
|
Faculté Informatique & Communications Cours de Programmation C++ -- J.-C. Chappelier |
Pour ceux qui veulent en savoir le minimum, juste pour que ça marche, voilà le strict minimum qu'il faut savoir (tous les autres sont invités à lire la suite) :
Makefile est juste un simple ficher texte (qui s'appelle simplement « Makefile » tout seul, sans extension), qui est automatiquement appelé par la commande make, et qui contient simplement la « liste des chose à faire » (on parle de « cible ») ;
Makefile décrit simplement une cible et ce qu'il est nécessaire d'avoir pour la réaliser (on parle de « dépendances »), au format :
cible: liste de dépendancesgateau au chocolat: farine oeufs beurre sucre chocolat levureet c'est tout ! Aussi simple que ça ! Sauf que pour nous, les cibles sont des fichiers exécutables et les dépendances sont des fichiers .o ; par exemple :
calculCplx: calculCplx.o complexe.o calculatrice.o
.o, donc) sont simplement le fichier .cc correspondant ainsi que la liste des fichiers .h nécessaires ; p.ex. :
calculatrice.o: calculatrice.cc calculatrice.h complexe.h
À noter que toutes les lignes cible-dépendances pour la compilation (uniquement) peuvent s'obtenir simplement en tapant la commande:
g++ -MM *.cc
all » et désigne tous les exécutables que vous souhaitez réaliser avec ce Makefile.
Makefile :CC = $(CXX) CXXFLAGS = -std=c++11 -pedantic -Wall
Au final, voici un exemple simple mais complet de Makefile :
CC = $(CXX) CXXFLAGS = -std=c++11 -pedantic -Wall all: calculCplx calculCplx: calculCplx.o complexe.o calculatrice.o # Ces lignes ont été recopiées de la commande g++ -MM *.cc complexe.o: complexe.cc complexe.h calculatrice.o: calculatrice.cc calculatrice.h complexe.h calculCplx.o: calculCplx.cc calcGUI.h
Et voilà !
Le code source d'un programme complet conséquent en C++ est, par souci de modularisation, souvent distribué dans plusieurs fichiers textes appelés « fichiers sources ». Les fichiers sources sont de deux sortes : les « fichiers d'en-tête » (header files, .h ou .hpp) et les fichiers principaux (.cc ou .cpp, souvent nommés « fichiers de définition », ou même simplement « fichiers sources », d'où une certaine confusion terminologique !). Tout ceci est « mis ensemble » par le compilateur (p.ex. g++) pour créer un programme exécutable à partir des codes sources.
Une paire (fichier d'en-tête .h, fichier principal .cc) correspondant à un concept donné est appelé « module ».
À quoi sert un fichier d'en-tête ?
À annoncer aux autres modules, les fonctionnalités apportées (on appelle cela l'API pour « Application Programming Interface ») par le module dont il fait partie.
Par exemple, un fichier matrice.h contiendra l'API du module concernant les matrices.
Dans les fichiers d'en-tête, on écrit typiquement :
#pragma once » (voir plus loin) ;Dans le fichier principal (avec l'extension .cc), on écrit typiquement :
Les fichiers d'en-tête ne sont donc pas compilés directement en du code machine, mais leur contenu est entièrement copié dans tous les autres modules qui en ont besoin. Ces autres modules (qui en ont besoin) demandent une copie d'un fichier d'en-tête en indiquant #include suivi par le nom de fichier en tête. Par exemple :
#include "matrice.h"dans un fichier source qui aurait besoin des matrices.
Cette copie est effectuée par le compilateur lors de la compilation du module qui demande l'inclusion.
La compilation d'un programme est composée de deux étapes principales :
l'étape de compilation proprement dite :
.o) ;Illustrons par deux exemples.
Dans vos exercices, vous utilisiez jusqu'à présent un seul fichier, par exemple exo1.cc (choisissez ici votre exercice préféré pour exo1)
Souvent (toujours?) ces programmes commencent par une directive #include <iostream> qui demande l'inclusion (= la copie) des définitions générales pour les entrées-sorties (io) usuelles, comme par exemple cout.
Les étapes de compilation puis d'édition de lien sont faites automatiquement (de façons transparente) lorsque vous compilez un tel programme dans Geany (ou dans votre environnement habituel). Mais faisons-les ici à la main de façon séparée pour comprendre.
D'abord, nous allons créer « les » fichier(s) objet(s) (ici, un seul, en fait) en utilisant la commande suivante :
g++ -c exo1.cc -o exo1.oL'option -c dit au compilateur de ne pas faire l'édition de liens, mais seulement la compilation (d'où le c comme « compile »). Cette option est suivi par le nom du fichier dont on veux créer le fichier objet, puis le nom que l'on veut pour fichier objet en question (l'option -o veut dire « output »).
Tapez cette commande dans un terminal (à l'endroit où se trouve votre fichier source C++) et vérifiez que le fichier objet est bien présent dans le répertoire. Inutile d'essayer de le lire où de l'ouvrir, c'est du code machine !
Ensuite, il faut liez les fichiers objets. Là, il y en a effectivement déjà plusieurs, sans que vous le sachiez : celui que vous venez de créer à partir de votre fichier source C++, mais aussi ceux des bibliothèques standard utilisées, qui sont automatiquement liés par le compilateur sans que nous ayons à les nommer explicitement.
Pour faire ces liens, nous utilisons simplement la commande suivante :
g++ -o exo1 exo1.oÀ nouveau, l'option -o suivie par le nom du fichier voulu (dans notre exemple, le fichier s'appelle exo1) sert a créer le programme exécutable portant ce nom. À noter que l'on peut mettre cette option et son nom de fichier associé où l'on veut dans la commande (ici nous les avons mis en premier, alors que dans l'exemple précédent, la compilation, nous les avions mis en dernier). Puis nous devons spécifier les fichiers à lier ensemble pour créer le programme exécutable. Dans notre exemple, il suffit de spécifier notre seul exo1.o (car les bibliothèques standard sont liées automatiquement).
Vérifiez que le programme exécutable a été crée avec succès et lancez-le depuis le terminal en tapant :
./exo1Un programme de taille importante est habituellement décomposé en plusieurs modules : en plus d'apporter de la clarté à l'organisation du programme, cette technique (appelée « conception modulaire ») permet de réutiliser des éléments (modules) pour différents programmes (par exemple, un module pour les matrices, un autre pour « demander un nombre », etc.).
Pour pratiquer cet aspect pas à pas, allez faire l'exercice 2 de la série 11 du second semestre.
Que se passe-t-il si par erreur ou indirectement un même en-tête de module est inclus plusieurs fois ? Par exemple, avez-vous déjà essayé de mettre deux fois un « #include <iostream> » dans un de vos programmes ?
Si les fichiers .h ne sont pas protégés contre cela (inclusions multiples), le compilateur risque de refuser de compiler, par exemple en raison de redéfinition d'un type/d'une classe défini(e) lors de la première inclusion.
Il est pour cela nécessaire de protéger vos fichiers .h contre les inclusions multiples en les faisant commencer par la ligne :
#pragma onceCela doit être la toute première ligne de vos fichiers .h.
Dans le cas de gros programmes (modulaires), compiler et lier le tout peut devenir fastidieux : il faut compiler chaque module (« compilation séparée ») dans son fichier objet, puis « lier » tous les fichiers objets produits. Et comme il est très probable que plusieurs modules fassent eux-mêmes appels à d'autres modules, la modification de l'un des modules peut rendre nécessaire de recompiler non seulement le module modifié, mais également ceux qui en dépendent, et cela récursivement, puis naturellement l'exécutable final.
L'outil make permet justement d'automatiser des enchaînement de commandes ayant des dépendances entre elles. Il peut être utilisé à bien des fins, mais son utilisation première (et celle qui nous intéresse ici) est la compilation de programmes (exécutables) à partir de fichiers sources. Il permet :
Pour pouvoir utiliser make, il suffit d'écrire, dans un simple fichier texte nommé Makefile (ou makefile), quelques règles simples décrivant les diverses dépendances du projet.
Voyons comment cet outil nous est présenté, par son manuel ;
man make
make [targets] [options] [macros_def]
L'action de l'utilitaire make est de déterminer automatiquement
quels portions d'un programme doivent être recompilées, et de réaliser
les commandes pour recompiler ces portions. [...] make peut être utilisé
avec n'importe quel language pour lequel un compilateur est disponible depuis
la ligne de commande. En fait, make n'est pas limité aux programmes.
Vous pouvez l'utiliser pour décrire n'importe quelle tâche pour laquelle
des fichiers doivent être automatiquement mis à jour à partir d'autres
fichiers, lorsque ces derniers ont été modifiés.
Pour utiliser make, vous devez au préalable écrire un fichier, appelé le makefile, explicitant les dépendances entre les fichiers de votre programme et les commandes permettant la mise à jour de chaque fichier. Typiquemment, dans un programme, les fichiers exécutables sont mis à jour à partir de fichiers objets, ces derniers étant produits par la compilation des fichiers sources. Dès l'instant où un makefile correct existe, chaque fois que vous changez l'un des fichiers sources, la simple commande : makesuffira pour réaliser l'ensemble des recompilations strictement nécessaires. L'outil make utilisera les règles indiquées dans le makefile ainsi que les dates de dernière modification des fichiers pour déterminer quels fichiers doivent être mis à jour. Pour chacun d'eux, il exécutera les commandes définies dans le makefile.
make exécute les commandes définies par le makefile
pour mettre à jour une ou plusieurs cibles, qui correspondent
typiquement à un programme. Si l'on ne précise pas le nom du fichier
makefile, à l'aide d'une option spécifique, make
prendra par défaut le fichier [extrait du "make man[ual]", trad. et adapt. libre]
|
Un Makefile (ou makefile) est essentiellement constitué de règles qui définissent, pour une cible donnée, l'ensemble des dépendances de la cible (c.-à-d. les éléments dont la cible dépend), ainsi que l'ensemble des commandes à effectuer pour actualiser la cible.
C'est un peu comme une liste de recettes de cuisine :
Mais ici nous ne faisons pas de cuisine. Si l'on illustre ces concepts avec l'exemple de l'exercice 2 de la série 11 du second semestre (programme factR par exemple), on aurait une règle pour l'édition de lien (programme factR), une autre règle pour la compilation de demander_nombre.cc (en demander_nombre.o), une autre règle pour la compilation de factorielleRecursive.cc (en factorielleRecursive.o), etc.
Pour la règle d'édition de lien, on aurait :
selection_sort array_filter.o, array_sort.o, array_std.o, swap.o et main.o
il faut que tous ces fichiers .o existent pour pouvoir produire l'exécutable selection_sort
Pour la règle de compilation de array_sort.c, on aurait :
array_sort.o array_sort.c, swap.h, array_filter.h (revoir la figure précédente, qui indique justement les dépendances) gcc -c array_sort.cLa syntaxe générale d'une règle est :
|
avec : |
|
|
|
make est appelé seul, sans indication de réalisation d'une cible particulière. make va donc rechercher dans le makefile
la première cible acceptable, en l'occurrence, all (effectivement, il existe des cibles
particulières qui ne sont pas acceptables en tant que cibles par défaut... mais ceci sort du
cadre de cette mini-référence). La règle de cette cible indique 2 dépendances, dep1
et dep2, qui n'existent pas (elles ne correspondent pas à des fichiers existants) ;
make va alors tenter de les réaliser, successivement.
dep1 ne possédant pas de dépendance, make passe immédiatement à l'exécution des
de commandes accompagnant la cible, à savoir l'affichage sur le terminal (au moyen de la commande
echo) de la chaîne "réalisation de la dépendance 1". Il en va de même pour la
seconde dépendance (dep2).
Une fois toutes les dépendances réalisées, make retourne à la réalisation de la cible initiale, all, dont il exécute les commandes.
Si l'on tape maintenant la commande
make dep3on obtient alors :
echo "banzai !"
banzai !
![]()
Dans cet exemple, la cible dep3
est spécifiée comme objectif lors de l'invocation de make. Cette cible ne possédant pas de
dépendance, make exécute sans autre le bloc de commandes relatif à la cible (affichage de
la chaîne "banzai !").
Remarquons au passage une petite différence de comportement entre nos deux exemples ; dans
le premier cas, on constate que la réalisation d'une cible se fait par l'exécution directe des
commandes, tandis que dans le second cas, make affiche préalablement la commande qu'il
va exécuter (echo "banzai !"). La raison de ce comportement tient au caractère @
précédant les commandes du premier cas, et absent dans le second cas. On en déduit donc que
make affiche dans un premier temps les commandes qu'il va exécuter pour réaliser une
cible, à moins que celles-ci ne soient préfixée par le caractère @.
Conseil : laissez toujours make afficher les commandes qu'il doit
réaliser (en particulier les compilations), sauf pour les commandes d'affichage pur, comme par exemple echo.
Tout cela est bien joli, mais à quoi ça sert « dans la vrai vie » puisqu'avec les règles par défaut on a vu qu'on n'avait rien besoin d'écrire ?
Certes, mais dans les projets plus compliqués, les règles par défaut ne suffisent plus.
Admettons que l'on ait écrit un programme implémentant une calculatrice pour nombres complexes, séparé en modules de la manière suivante :
libgraph.h, et d'un fichier d'archive binaire,
libgraph.a (statique) ou libgraph.so
(dynamique).
complexe.h (header)
et le fichier d'implémentation complexe.cc ;
calculatrice.h, dépendant de
complexe.h, et calculatrice.cc (sans dépendance) ;
calcGUI.h, dépendant de calculatrice.h
et de libgraph.h, et calcGUI.cc ;
main()), fournit par
le fichier calculCplx.cc, dépendant de
calcGUI.h .
#include ....cc) dépend de plus du fichier
de définition (.h) auquel il est associé.
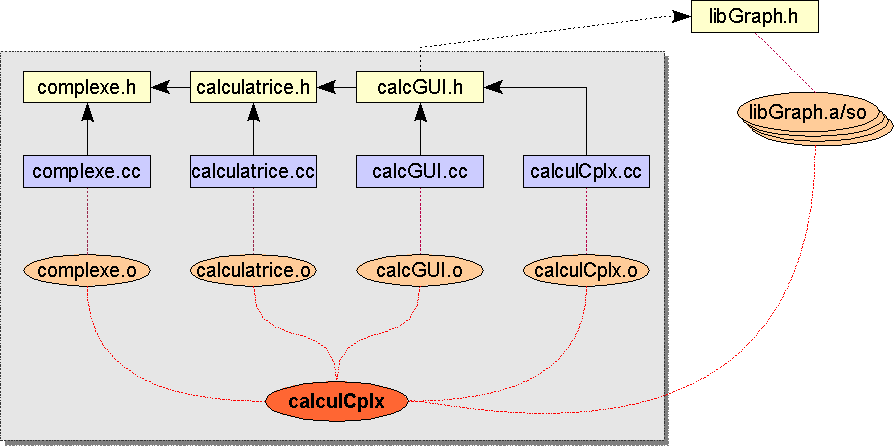
Pour écrire un Makefile acceptable, il nous suffit de faire une cible
pour chaque module, soit une cible par fichier objet résultant de la compilation du
fichier d'implémentation, et une cible supplémentaire pour lier le tout en un programme
exécutable.
Les dépendances de chacune de ces cibles sont déterminés par les directives
d'inclusion présentes dans les fichiers de déclaration et d'implémentation concernés,
mais on ne considère que les dépendances vis-à-vis des éléments susceptibles d'être
modifiés dans le cadre de notre projet (on ignore donc les dépendances vers la librairie
graphique, comme d'ailleurs celles envers les éléments de la librairie standard) ;
les commandes de mise à jour sont naturellement
l'instruction de compilation des cibles.
Un Makefile possible pourrait donc être (voir ici pour une version finale plus compacte) :
all: calculCplx complexe.o: complexe.cc complexe.h calculatrice.o: calculatrice.cc calculatrice.h complexe.h calcGUI.o: calcGUI.cc calcGUI.h calculatrice.h calculCplx.o: calculCplx.cc calcGUI.h calculCplx: calculCplx.o complexe.o calculatrice.o calcGUI.o g++ -o calculCplx calculCplx.o complexe.o calculatrice.o calcGUI.o -lgraph |
make. On remarque que la cible all
n'est dans ce cas qu'un simple alias pour la cible calculCplx.make une seconde
fois, après la première compilation, le programme signalera :
make: Nothing to be done for `all'.De la même manière, si l'on venait à modifier le fichier
complexe.cc,
la commande make ne conduirait qu'à la recompilation de
ce dernier (réalisation de la cible complexe.o, puisque l'un
de ses dépendances, complexe.cc correspond à un fichier dont la date de modification
est postérieure à celle du fichier attaché à la cible), entraînant elle-même la
mise à jour de la cible calculCplx (pour la même raison
que précedemment).complexe.h, ce seront
les cibles complexe.o, calculatrice.o
et calculCplx qui seront mise à jour.
La syntaxe générale de définition d'une variable dans un Makefile est :
| avec : |
|
Notons également que pour le make de GNU (aussi appelé gmake),
la syntaxe suivante permet d'ajouter un ou plusieurs éléments à la liste des
valeurs associées à une variable :
| NOM_VAR += valeurs |
$ ;
| $(NOM_VAR) |
Supposons que nous souhaitions systématiquement préciser un certains nombres d'options
au compilateur, pour permettre l'utilisation d'un dévermineur (-g), forcer une
optimisation de niveau 2 du code compilé (-O2), et rendre le compilateur plus strict
vis à vis d'éventuels non respect de la norme C++11 dans notre code (-std=c++11 -pedantic -Wall).
(Note : si votre compilateur le supporte, vous pouvez utiliser une norme plus récente, p.ex. -std=c++17.)
Plutôt que d'ajouter chacune de ces options à chaque commande de compilation (et devoir
à nouveau tout remodifier lorsque l'on désirera supprimer les informations additionnels
ajoutées pour permettre le déverminage), il serait plus judicieux d'utiliser une variable
(par exemple CXXFLAGS, qui est le nom utilisé par défaut par make) pour mémoriser les options à transmettre
au compilateur. Notre Makefile deviendrait alors :
CXXFLAGS = -std=c++11 -pedantic -Wall CXXFLAGS += -O2 CXXFLAGS += -g all: calculCplx complexe.o: complexe.cc complexe.h calculatrice.o: calculatrice.cc calculatrice.h complexe.h calcGUI.o: calcGUI.cc calcGUI.h calculatrice.h calculCplx.o: calculCplx.cc calcGUI.h calculCplx: calculCplx.o complexe.o calculatrice.o calcGUI.o g++ -o calculCplx calculCplx.o complexe.o calculatrice.o calcGUI.o -lgraph |
Ce qui a été présenté jusqu'à maintenant est suffisant pour vous permettre d'écrire
un Makefile fonctionnel ; cependant, comme l'illustre l'exemple précédent,
cette rédaction reste relativement fastidieuse. Les informations contenue dans cette
section vont vous permettre d'augmenter considérablement le pouvoir expressif des
instructions du Makefile, rendant ainsi sa rédaction plus aisée.
Il est possible d'ajouter des commentaires (orientés lignes, c.-à-d. comme les //... de C++)
dans un Makefile, en marquant le début de commentaire par le symbole #.
Remarquons que les commentaires dans les lignes de commandes ne sont pas retiré par make
avant leur exécution par le shell ; c'est donc ce dernier qui décidera ce qu'il convient
d'en faire :
|
|
\ à la fin de la ligne
à étendre :
|
|
On constate avec cet exemple qu'un usage maladroit de cette possibilité
peut considérablement nuire à la lisibilité du Makefile.
make maintien automatiquement à jour pour nous un certain nombre de variables prédéfinies, en les actualisant lors de l'exécution de chaque règle, en fonction de la cible concernée et de ses dépendances.
Parmi ces variables, citons :
$@ |
nom de la cible (du fichier) de la règle courante. |
|---|---|
$< |
nom de la première dépendance |
$? |
liste de toutes les dépendances (séparées par une espace) plus récentes que la cible courante (les dépendances impliquant la mise à jour de la cible). |
$^ |
liste de toutes les dépendances (séparée par une espace) de la cible. Si une dépendance est présente plusieurs fois dans une même liste de dépendances, elle ne sera reportée qu'une seule fois par $^. |
$+ |
liste exacte de toutes les dépendances (séparée par une espace) de la cible (à l'inverse de $^, les dépendances sont reportées par $+ autant de fois qu'ils sont indiqués dans la liste des dépendances). |
CXXFLAGS = -std=c++11 -pedantic -Wall CXXFLAGS += -O2 CXXFLAGS += -g all: calculCplx complexe.o: complexe.cc complexe.h calculatrice.o: calculatrice.cc calculatrice.h complexe.h calcGUI.o: calcGUI.cc calcGUI.h calculatrice.h calculCplx.o: calculCplx.cc calcGUI.h calculCplx: calculCplx.o complexe.o calculatrice.o calcGUI.o g++ -o $@ $^ -lgraph |
| compilation C++ |
la cible file.o sera automatiquement réalisée à partir du fichier file.cc au moyen d'une commande de la forme : $(CXX) -c $(CPPFLAGS) $(CXXFLAGS) -o file.o file.cc qui peut encore se simplifier en $(COMPILE.cpp) -o file.o file.cc |
| création d'exécutable |
une cible file pourra être automatiquement réalisée
à partir du fichier objet file.o, ou d'un ensemble
de fichiers objets (spécifiés dans la liste des dépendances) dont
file.o fait partie, comme par exemple
x.o file.o z.o, au moyen d'une commande de
la forme :
$(CC) $(LDFLAGS) -o file file.o x.o z.o $(LOADLIBES) $(LDLIBS) |
| création d'exécutable |
une cible file pourra être automatiquement réalisée
à partir du fichier source file.c, et éventuellement
d'un ensemble de fichiers objets (spécifié dans la liste des dépendances),
tels y.o z.o
au moyen d'une commande de la forme :
$(CC) $(CPPFLAGS) $(CFLAGS) $(LDFLAGS) -o file file.c y.o z.o $(LOADLIBES) $(LDLIBS) |
| création d'exécutable |
une cible file pourra être automatiquement réalisée
à partir du fichier source file.cc, et éventuellement
d'un ensemble de fichiers objets (spécifié dans la liste des dépendances),
tels y.o z.o
au moyen d'une commande de la forme :
$(CXX) $(CPPFLAGS) $(CXXFLAGS) $(LDFLAGS) -o file file.cc y.o z.o $(LOADLIBES) $(LDLIBS) qui peut se simplier en $(LINK.cpp) -o file file.cc y.o z.o $(LOADLIBES) $(LDLIBS) |
cc, tandis que $(CXX)
se voit elle associée la commande de compilateur C++, c.-à-d. g++ sur les machines que vous utilisez.
On peut donc transformer notre Makefile pour le rendre
encore plus concis, de la manière suivante :
CPPFLAGS = -std=c++11 -pedantic -Wall CPPFLAGS += -O2 CPPFLAGS += -g all: calculCplx complexe.o: complexe.cc complexe.h calculatrice.o: calculatrice.cc calculatrice.h complexe.h calcGUI.o: calcGUI.cc calcGUI.h calculatrice.h calculCplx.o: calculCplx.cc calcGUI.h calculCplx: calculCplx.o complexe.o calculatrice.o calcGUI.o $(LINK.cpp) -o $@ $^ -lgraph |
![]() Remarquons que nous avons tout de même du définir la commande utilisée pour
produire l'exécutable («édition de liens»), puisque notre programme est en C++ et non pas en C qui est le langage considéré par défaut sur les machines des salles CO.
Pour éviter cela, on peut envisager plusieurs solutions, dont la plus simple est de brutalement changer la commande associée à la variable
$(CC) en
Remarquons que nous avons tout de même du définir la commande utilisée pour
produire l'exécutable («édition de liens»), puisque notre programme est en C++ et non pas en C qui est le langage considéré par défaut sur les machines des salles CO.
Pour éviter cela, on peut envisager plusieurs solutions, dont la plus simple est de brutalement changer la commande associée à la variable
$(CC) en $(CXX)
En d'autres termes, on peut réduire notre Makefile de la manière suivante :
CC=$(CXX) CXXFLAGS = -std=c++11 -pedantic -Wall CXXFLAGS += -O2 CXXFLAGS += -g LDLIBS = -lgraph all: calculCplx calculCplx: calculCplx.o complexe.o calculatrice.o calcGUI.o complexe.o: complexe.cc complexe.h calculatrice.o: calculatrice.cc calculatrice.h complexe.h calcGUI.o: calcGUI.cc calcGUI.h calculatrice.h calculCplx.o: calculCplx.cc calcGUI.h |
Le corrolaire de cela est qu'avec un tel Makefile
vous ne pouvez plus, sans autre, produire
d'exécutables à partir de programmes en langage C...
mais ce n'est pas grave pour notre cours.
En dépit du nom de la section précédente, nous sommes cependant encore loin d'avoir fait le tour des possibilités de make.
Pour ceux qui voudrait en savoir plus, n'hésitez donc pas à consulter les références (toutes externes) suivantes :
Finalement, notez qu'il existe de nombreuses refontes plus modernes d'outils de gestion de projets de développement (CMake, SCons, GNU autotools, outils intégrés dans des IDE : KDevelop, Anjunta, NetBeans, Code::Blocks, …), mais nous pensons qu'une bonne connaissance de la base make est un bonus à votre formation.